The Philosophical Gourmet Report has been ranking graduate institutions in philosophy since 2006. This history enables us to ask questions about how Institutions’ mean scores changed over time: Which Institutions saw the greatest change in their mean score over time? Which saw the least? Did the greatest changes in mean score tend to be positive, negative, or a mix? Does the range of mean scores for institutions follow any pattern? On this page, I’ll document my process for analyzing the mean score range for each Institution, divided up as follows. The summary results without all the steps can be found on the PGR Database Project main page.
Contents
- The Process
- Institutions with the largest mean score fluctuation
- Institutions with the smallest mean score fluctuation
- Distribution of
mean_rangescores
The Process
In order to arrive at these results, I needed to 1) group mean scores by institutions, 2) identify the minimum and maximum mean scores for each institution, 3) calculate the difference or range between minimum and maximum mean scores, and then 4) rank institutions based on the range of mean scores. I could then figure out which institutions had the highest and lowest range of mean scores and perform any other analysis I would like to do.
To accomplish this, I decided the best thing to do would be to create a new junction table that contained the min, max, and range of the mean scores for each institution. To create and populate the table, I used a Python script that can be found on my Github page, though I’ll walk through it here.
First, we’ll want to load the relevant package, sqlite3 , and create the table.
import sqlite3
#Connect to PGR database
connection = sqlite3.connect('pgr-db-2.db')
# Creating a cursor object to execute
# SQL queries on a database table
cursor = connection.cursor()
#Create table for institution spread
create_table = ''' DROP TABLE IF EXISTS Mean_Range; CREATE TABLE Mean_Range(
"institution_id" INTEGER PRIMARY KEY,
"max_mean" NUMERIC,
"min_mean" NUMERIC,
"mean_range" NUMERIC)
'''
cursor.executescript(create_table)
This table could eventually include more summary statistical data for each institution, and so I might eventually want to rename it, but for now I’ve just called it “Mean_Range” and given it four attributes: institution_id, min_mean, max_mean, and mean_range.
Next, I set the variables for the SQL statements I plan to run in the for loop with cursor.execute(), just to keep the for loop clean:
#SQL variables for min and max mean acquisition and insertion
get_max_mean = '''SELECT MAX(mean) FROM Overall WHERE institution_id = ? '''
get_min_mean = '''SELECT MIN(mean) FROM Overall WHERE institution_id = ? '''
insert_range = "INSERT OR IGNORE INTO Mean_Range (institution_id, max_mean, min_mean, mean_range) VALUES ( ?, ?, ?, ? )"
I then needed to get all the institution ID numbers to use in the new table. I’m not sure if this is the best way to do this, but I settled on using a SELECT statement for all institution_id values from the Overall table and converted them to unique list items I could then iterate through:
#Identify all institution IDs and put them in a list
cursor.execute("SELECT institution_id FROM Overall")
inst_id_tups = cursor.fetchall()
#convert institution ID tuples into integers w/o dupilcates
inst_id_list = []
for item in inst_id_tups:
if item[0] not in inst_id_list:
inst_id_list.append(item[0])
Now comes the magic part: The program iterates through each list item and uses that to lookup the minimum and maximum mean score using the SELECT statements in the variables get_max_mean and get_min_mean, before then calculating the difference between the minimum and maximum, and finally inserting all the values into the table:
#List min, max, and difference btwn mean values for a particular institution_id
for item in inst_id_list:
cursor.execute(get_max_mean, ( item, ))
max_mean = cursor.fetchone()[0]
cursor.execute(get_min_mean, ( item, ))
min_mean = cursor.fetchone()[0]
diff = max_mean - min_mean
print("Institution ID", item, "Max", max_mean, "Min", min_mean, "Difference", round(diff, 2))
#Add the values to the Spread table
cursor.execute(insert_range, ( item, max_mean, min_mean, round(diff, 2) ) )
connection.commit()
The result is a new table in our database that includes the four attributes, which looks like this in DB Browser:
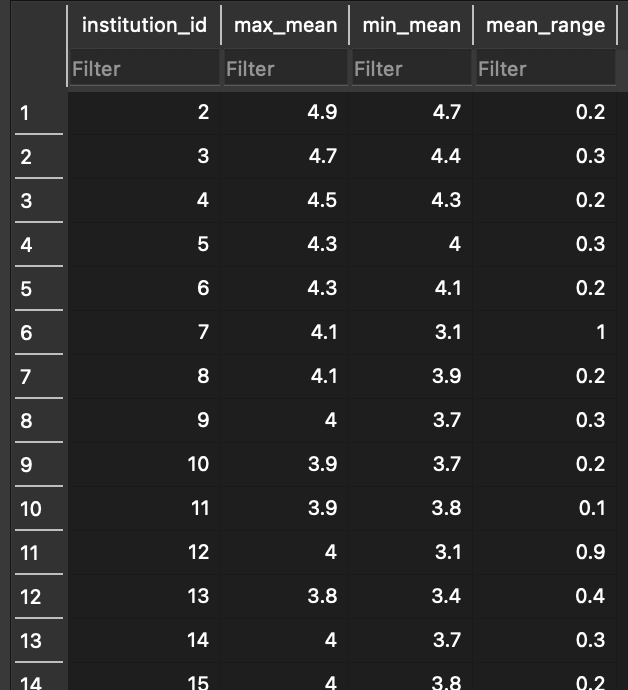
Now we have to make the data a bit more fit for human consumption, which involves just a bit of SQL and some help from ggplot in R. The first query that makes sense to run replaces institution IDs, lists the attributes from the new table, with names and sorts them by mean_range to identify the institutions with the biggest swing in mean score throughout the PGR’s iterations:
SELECT Institution.name, Mean_Range.max_mean, Mean_Range.min_mean, Mean_Range.mean_range
FROM Institution JOIN Mean_Range ON Institution.id = Mean_Range.institution_id
ORDER BY Mean_Range.mean_range DESC
The results for the top ten look like this:

So now we can use our Mean_Range table to identify which schools saw the greatest fluctuation in their mean scores since 2006. With the key data point identified, we can now turn towards analysis.
Institutions with Largest Mean Score Fluctuation
Based on the table results of the top 10 mean_range scores, and scrolling down a bit, we can see that there are only 4 Institutions with mean_range values of 0.8 or above. There are many more Institutions with values of 0.7 or less, so we’ll just focus on the top 4 for this initial analysis. To perform the analysis and create the visualization, I needed to pull up the full Overall records for each year for the top 4 Institutions using the following query:
SELECT Institution.name, Overall.mean, Overall.overall_rank, Mean_Range.mean_range, Year.year, Region.region
FROM Institution JOIN Overall JOIN Year JOIN Region JOIN Mean_Range
ON Institution.id = Overall.institution_id AND Overall.region_id = Region.id
AND Overall.year_id = Year.id AND Institution.id = Mean_range.institution_id
WHERE Mean_Range.mean_range > 0.7
ORDER BY Mean_Range.mean_range DESC, Institution.name, year DESC
This gives us the following result, which shows the mean scores for each year, the overall rank, the mean range, year, and region, for each institution:
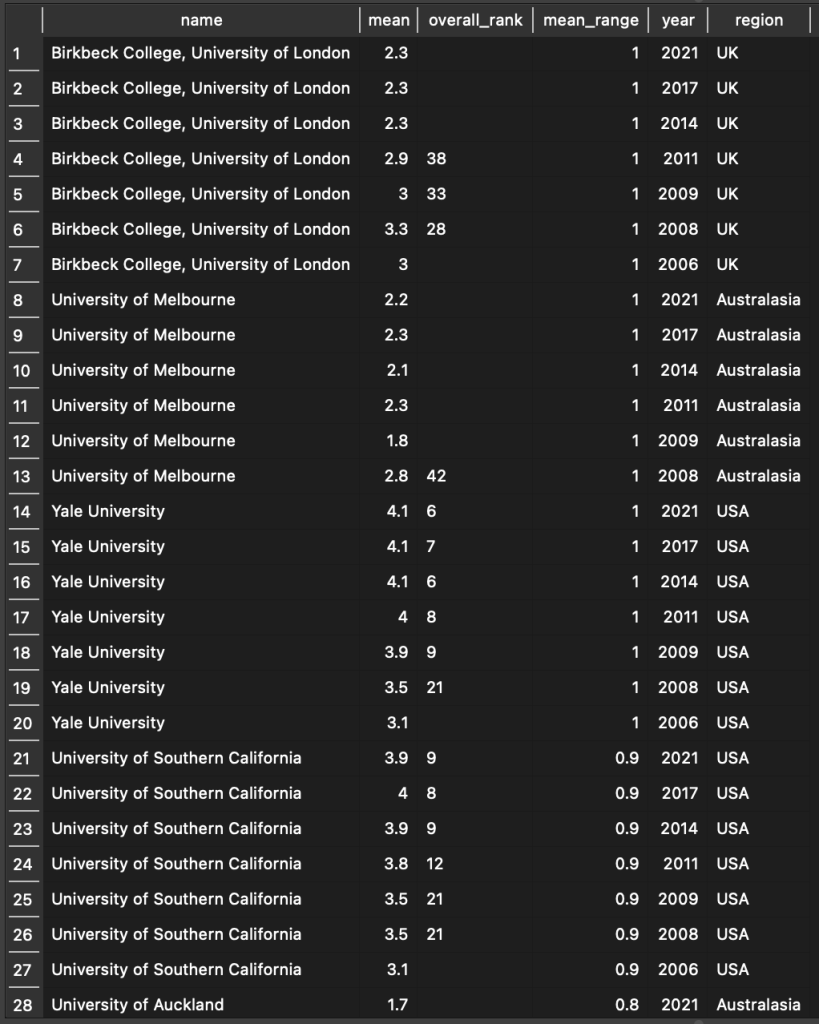
We can see that 4 institutions had mean score ranges of 0.9 points or above. To better visualize the data, I just exported the view from DB Browser as a csv file and used ggplot2 to make the plot in R:
highest_range <- read.csv("highest_range.csv")
ggplot(data=highest_range, aes(x=year, y=mean, color=name)) +
geom_line(size=1)+
geom_point(color="black")+
geom_text(aes(label=mean), color="black", nudge_y=0.06)+
theme_bw()+
xlab("Year")+
ylab("Mean")+
guides(color = guide_legend(title = "Institution Name"))+
labs(title = "Highest Range of Mean Scores",
subtitle="Mean scores over time for Institutions with the highest range of mean scores",
caption = "Data Source: The Philosophical Gourmet Report")
Which looks like this:
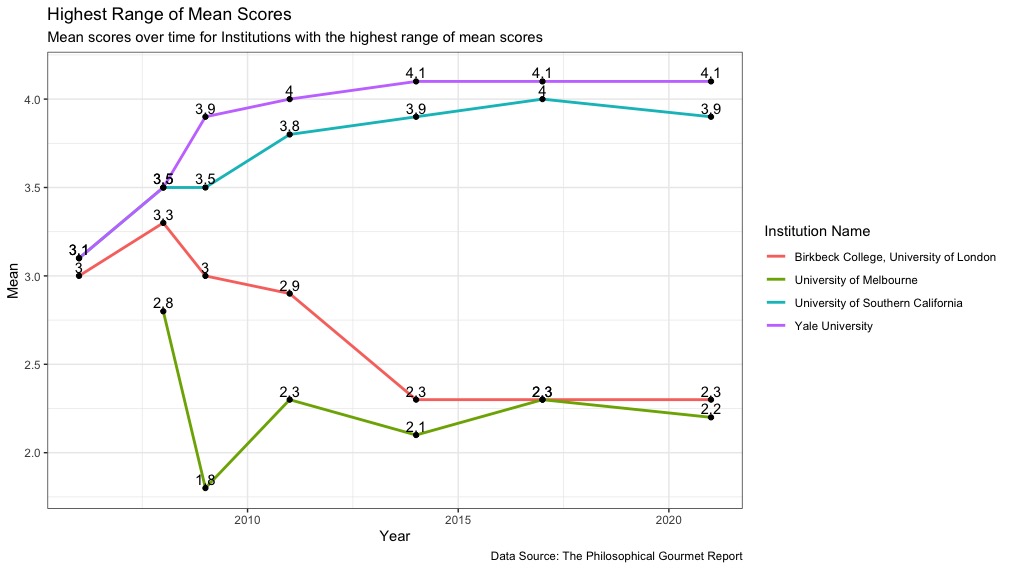
Each line tells a different story for each institution, and they’re all quite different!
- Yale University (2021 overall rank 6) had a spread of 1-point over a cumulative increase in its mean score since 2006, which is the highest mean range of any institution. It began in 2006 with a score of 3.1, but then jumped up to 3.9 in 2009, and has edged upwards ever since, settling in at 4.1 for the past 3 iterations of the PGR.
- The University of Southern California (2021 overall rank 9) increased its mean score by 0.9 between 2006 and 2017, from 3.1 to 4, but its score went down to 3.9 in 2021.
- Birkbeck College, University of London began with a score of 3 in 2006, went up to 3.3 in 2008, but then began trending downward 1 whole point between 2008 and 2021.
- The University of Melbourne saw a massive drop in its score between 2008 and 2009. I wonder what happened! I suppose there must have been some major faculty moves.
- The 4 institutions with the largest mean score range occurred across the overall rankings, with representatives near both the top and bottom of the overall mean scores.
Institutions with the smallest mean score fluctuation
Now suppose we were interested in the Institutions whose overall mean scores changed the least since 2006. Our first thought might be to run the same query we did above and simply order the Institutions by mean range ascending, like so:
SELECT Institution.name, Overall.mean, Overall.overall_rank, Mean_Range.mean_range, Year.year, Region.region
FROM Institution JOIN Overall JOIN Year JOIN Region JOIN Mean_Range
ON Institution.id = Overall.institution_id AND Overall.region_id = Region.id
AND Overall.year_id = Year.id AND Institution.id = Mean_range.institution_id
ORDER BY Mean_Range.mean_range ASC, Institution.name, year DESC
Which gives us the following result:
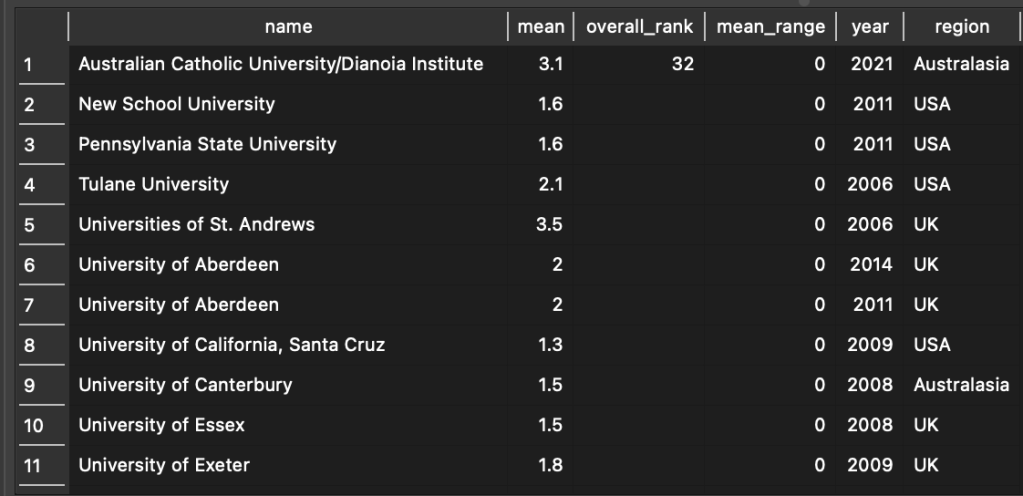
But we have a problem: Most, but not all, Institutions with a mean_range score of 0 have records for only one year! So we have to somehow filter those out and only show results where an Institutions’ mean score has stayed stable over multiple iterations of the PGR. To do so, we can use a nested SELECT as part of our WHERE clause to only include Institutions with more than one mean score in their records:
SELECT Institution.name, Overall.mean, Overall.overall_rank, Mean_Range.mean_range, Year.year, Region.region
FROM Institution JOIN Overall JOIN Year JOIN Region JOIN Mean_Range
ON Institution.id = Overall.institution_id AND Overall.region_id = Region.id
AND Overall.year_id = Year.id AND Institution.id = Mean_range.institution_id
AND Overall.institution_id IN
( SELECT Overall.institution_id FROM Overall GROUP BY Overall.institution_id HAVING COUNT(Overall.mean) > 1)
ORDER BY Mean_Range.mean_range DESC, Institution.name, year DESC
Additionally, we only want results whose mean_range scores are less than 0.2, since that is a much more common value than 0.1 or below, which only applies to 4 Institutions. Once we add in the WHERE clause, WHERE Mean_Range.mean_range < 0.2, the query gives us the following results:
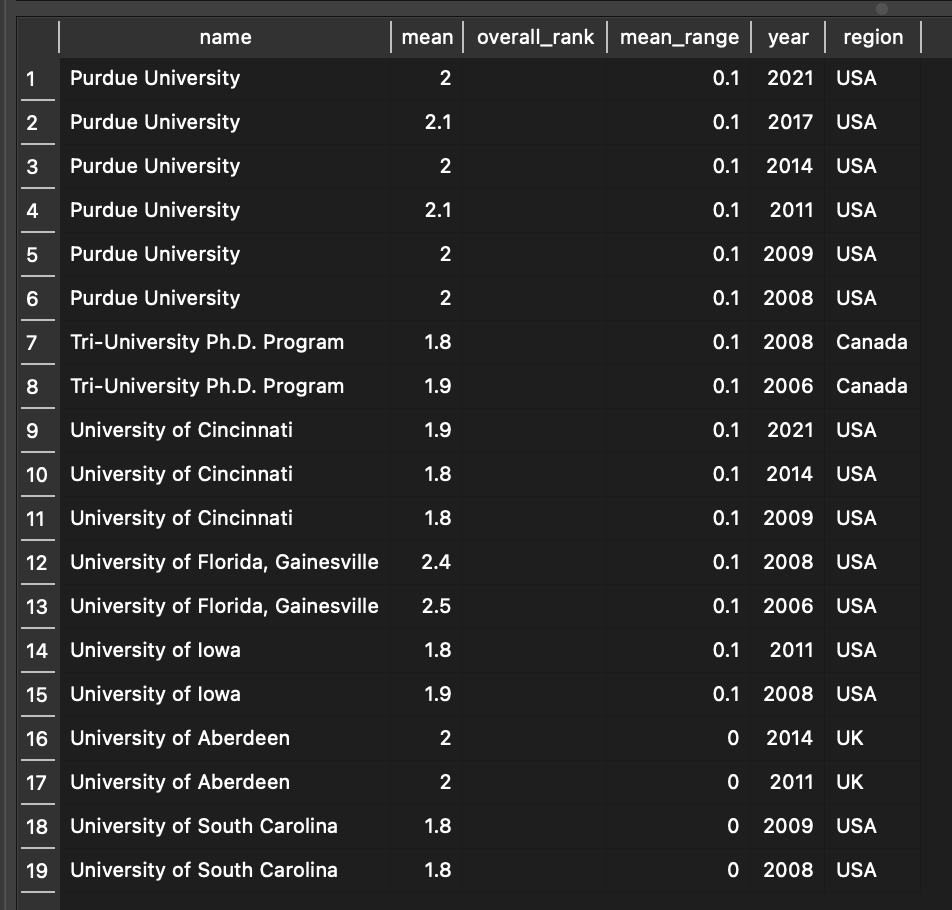
But we have another problem here: Most of the institutions with ranges of 0.1 or 0 only have two entries, and have relatively low scores. We can surmise that these institutions were included in the rankings when their scores were high enough to be included, but otherwise weren’t. Thus, they don’t really represent institutions with low mean fluctuation. The only institutions with more than 3 entries and a mean score range of 0.1 or less are Purdue University and the University of Cincinnati. To visualize this, I simply used the same script as above but with a different CSV file including only those two universities that meet the conditions:
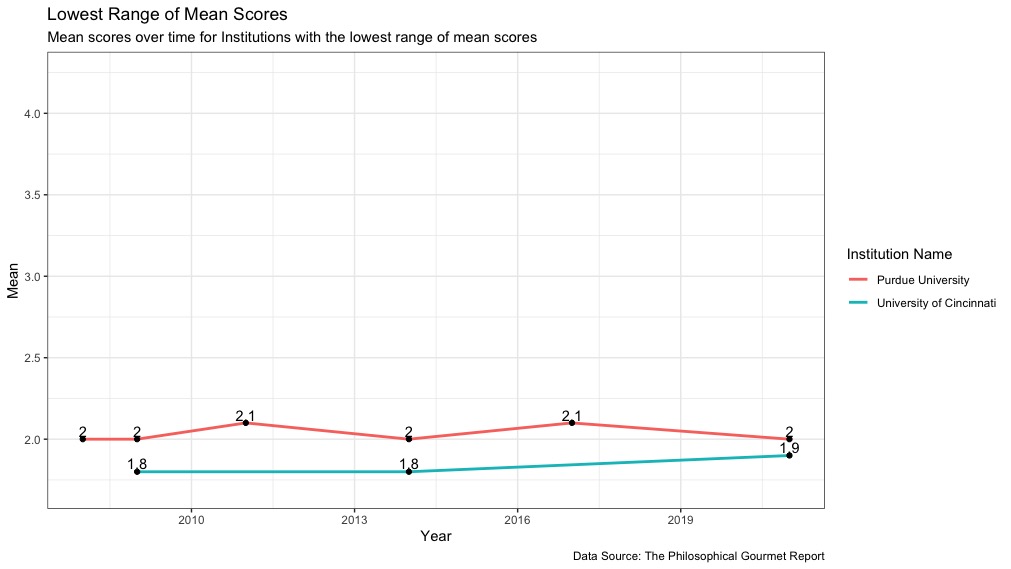
With the visualization complete, we can conclude the following:
- Purdue University‘s overall mean score has fluctuated between 2 and 2.1 since 2009.
- The University of Cincinnati’s overall mean score has gone from 1.8 in both 2009 and 2014 to 1.9 in 2021.
Distribution of mean_range scores
I was also interested to see if there were any patterns in the distribution of the mean_range scores. For example, what was the most common amount of fluctuation for an Institution? Also, I wondered if there was any correlation between the mean score fluctuation and the perceived quality of the department overall. To answer these questions, I needed a histogram, a table, and a scatter plot. The table was easy enough to generate with a SQL query.
SELECT Mean_range.mean_range, COUNT(Mean_range.mean_range)
FROM Mean_range
GROUP BY Mean_range.mean_range
ORDER BY Mean_range.mean_range
The only problem was that I still had the extra values for Institutions with a value of 0 for mean_range. To fix this, I just had to add back in the WHERE clause that I used before:
SELECT Mean_range.mean_range AS "Mean_Range", COUNT(Mean_range.mean_range) AS "Count"
FROM Mean_Range
WHERE Mean_range.institution_id IN
( SELECT Overall.institution_id FROM Overall JOIN Institution
ON Institution.id = Overall.institution_id AND Institution.id = Mean_range.institution_id GROUP BY Overall.institution_id HAVING COUNT(Overall.mean) > 1)
GROUP BY Mean_range.mean_range
ORDER BY Mean_range.mean_range
Which gave me the following result:
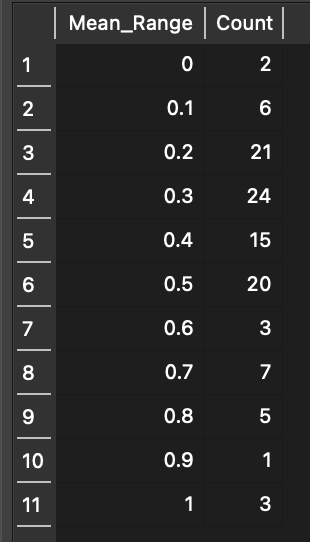
So we can see from this table that the most common values cluster around the lower half of the mean range scores. I chose to visualize this in a few different ways with RStudio. The first was with a histogram and density curve like so:
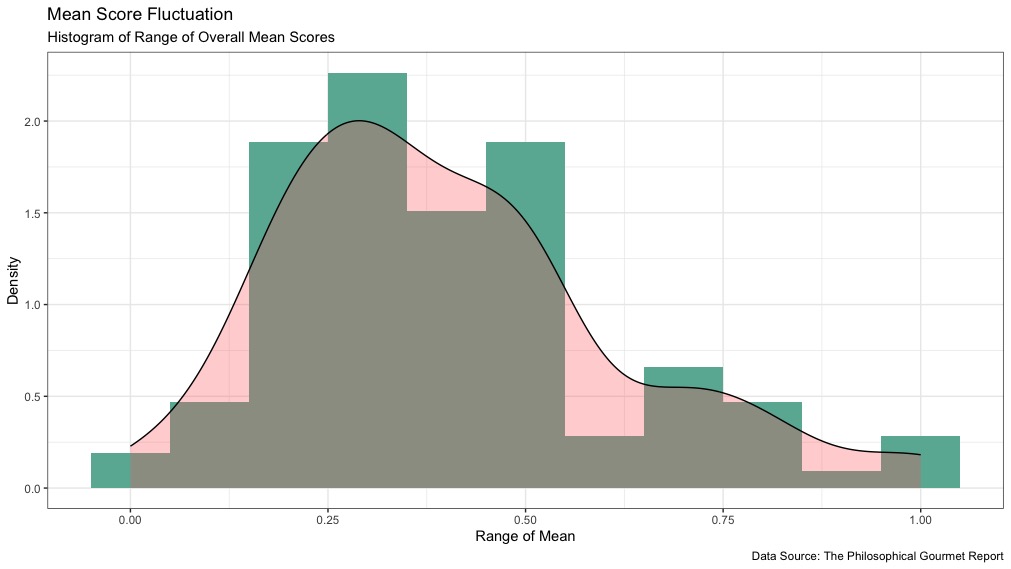
We can now clearly see the distribution of the mean_range scores favoring those between 0.2 and 0.5. I calculated that 74.77% of scores falling within this range. According to all the PGR data, only 25% of Institutions fluctuated greater than 0.5 points or less than 0.2 points in their overall mean scores. That is a remarkably precise range!
My next question was whether or not this distribution tracked the quality of departments overall. That is, did higher or lower ranked departments tend to fluctuate more? To figure this out, I queried the database to show me the names of institutions, their mean_range scores, and the average of their overall mean scores. This would allow me to plot the mean_range against the overall quality of the department. The average mean score will probably be useful in the future, but for now I don’t think it needs a table of its own. At the same time, I thought it would be a good idea to calculate the range as a percentage of fluctuation from the average mean score. This was also something I just elected to do in SQL rather than by creating another table. The whole query looks like this:
SELECT Institution.name, Mean_Range.mean_range, ROUND(AVG(Overall.mean), 2) AS avg_mean,
ROUND(mean_range.mean_range/AVG(Overall.mean)*100, 2) AS percent_fl, Region.region
FROM Institution JOIN Overall JOIN Mean_Range JOIN Region
ON Institution.id = Overall.institution_id AND Overall.region_id = Region.id
AND Institution.id = Mean_range.institution_id
GROUP BY Institution.name
HAVING COUNT(Overall.mean) > 1
ORDER BY Mean_Range.mean_range DESC, AVG(Overall.mean) DESC
The results looked like this:

Introducing the percent change value is interesting because it shows that, e.g., although Yale University had among the largest range of mean scores, with a 1 point mean_range score, lower mean_range scores at other Institutions represented a larger percentage of their mean scores on average. In other words, a 1 point swing for Yale University was a lower percentage of its overall score (26.12%) than was a 0.8 point swing for the University of Aukland (36.92%). On average, Institution scores had a Relative Percent Difference (RPD) of 9.09%, meaning that there was a 9.09% window around their average score.
I then exported the results view as a CSV file and used RStudio to create a scatter plot of the mean range against the avg_mean value, giving the following results:
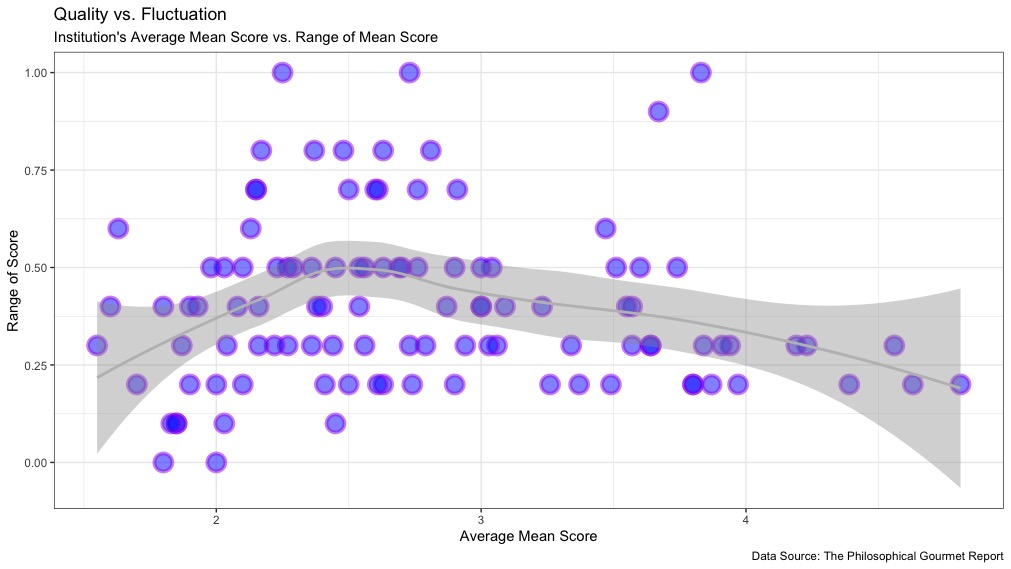
The plot and the trend-line both show that Institutions with higher and lower overall scores on average tended to fluctuate less, while schools with an average mean score between 2 and 3 tend to see the most fluctuation. There is generally less fluctuation among institutions with average scores of 3 or above. (It’s worth keeping in mind as well that the data at the lower end of the Average Mean Score is less reliable, since those Institutions are more likely not have a complete set of scores, as we saw previously.)
This result becomes more obvious when we instead interpret the range of the mean score as a percentage of the average mean score:
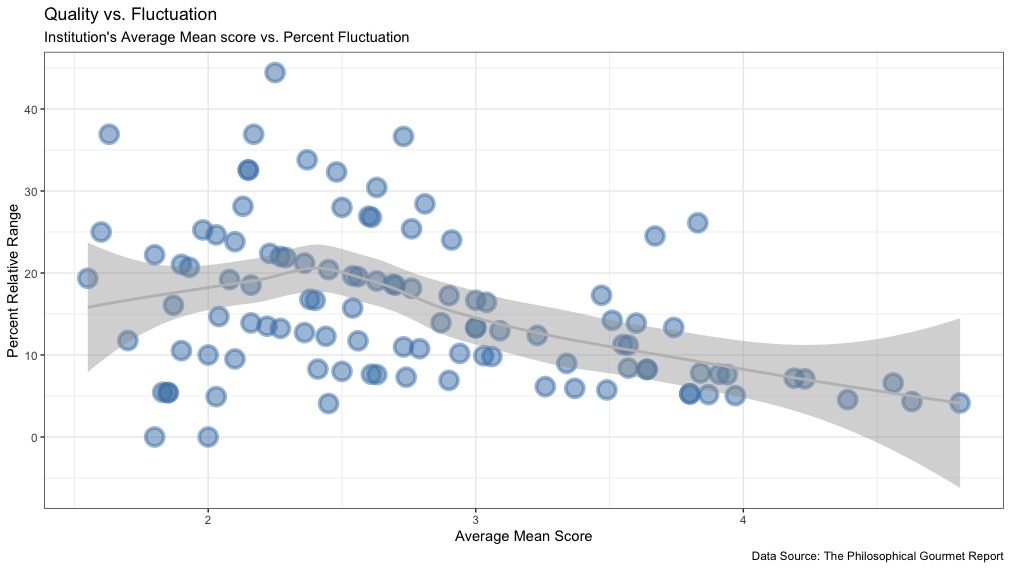
Here, we can clearly see the lines overall trend downwards. Institutions with higher overall scores tended to fluctuate less, while institutions with lower overall scores tended to fluctuate more. (Though institutions with scores below 2 tend to fluctuate less than those with scores between 2 and 3 and are generally less reliable since many have data for only 2 iterations.)
What could explain this trend? I see at least two possible explanations:
- Institutions with lower rankings have higher faculty turnover rates, and thus their scores tend to fluctuate more. If overall quality is a product of faculty quality, then high quality fluctuation implies high turnover. Assuming that the best departments tend to have better faculty retention, this makes good sense. But that’s just an assumption, and one that could presumably be informed by data.
- As we saw with my earlier Visualizations, quality and quantity tend to track one another in philosophy departments. Thus, even if the rates of faculty turnover are similar across PGR ranked departments, we wouldn’t see the same fluctuation in scores at the large, high-scoring departments that we would at smaller and lower-scoring ones.
I think both of these factors probably play a role in the tendency for higher-ranked departments to not fluctuate too much. Both explanations rely on uncorroborated assumptions about faculty retention, but I think the second explanation is overall safer.
Notes:
- The queries and scripts I used can all be found on Github.
- Nothing here should be interpreted as advice about which graduate institution or program to pursue.
